DMflow.chat
廣告
DMflow.chat:智慧客服新時代,輕鬆切換真人與 AI!持久記憶、客製欄位、即接資料庫表單,多平台溝通,讓服務與行銷更上一層樓。
AI 翻譯哪家強?別再憑感覺!首個工業級 AI 翻譯評測系統 TransBench 正式發布,從通用標準、電商特性到文化細節,全方位檢驗模型實力。GPT-4o 領跑,DeepL、Qwen 各顯神通,快來看看誰是翻譯界的真功夫!
你知道嗎?在這個全球化咻咻咻發展的時代,語言不再是隔閡,AI 翻譯工具簡直成了我們跨文化交流的神隊友。從日常溝通到跨境電商,AI 翻譯的身影無所不在。但問題來了,市面上的翻譯模型五花八門,到底哪個才是真材實料、哪個只是虛有其表?我們普通用戶常常看得一頭霧水,對吧?
老實說,以前的翻譯評測,比較像是實驗室裡的考試,雖然也有參考價值,但跟實際應用場景總有點距離。不過現在,這個局面可能要被打破了!
最近,由阿里巴巴國際 AI 業務團隊、上海人工智能實驗室以及北京語言大學聯手打造的首個工業級應用導向的 AI 翻譯評測系統——TransBench——正式跟大家見面了!這可不是隨便玩玩的,TransBench 的目標很明確:就是要給業界一個看得懂、用得上的翻譯品質標準。
你可能會想,不就是個翻譯評測嗎?有什麼特別的?
特別之處可多了!TransBench 不再只看翻譯的「信達雅」這種比較傳統的標準,它更接地氣,引入了像是幻覺率(Hallucination Rate)、文化禁忌詞、敬語規範這些在實際應用中超級關鍵的新指標。
讓我解釋一下:
這些指標,都是從真實的使用場景中提煉出來的血淚經驗啊!
TransBench 是怎麼評估一個翻譯模型夠不夠格呢?它主要從三個核心維度來下手:
而且,TransBench 的武器庫裡還有秘密武器——穩定性攻擊數據!這裡面包含了各種拼寫錯誤、詞序混亂、術語錯誤的「搗蛋」文本,就是要看看這些 AI 模型在面對不完美的輸入時,還能不能保持冷靜,給出靠譜的翻譯。畢竟,真實世界的使用者哪有那麼完美,打錯字、語法不順暢都是家常便飯嘛!
說了這麼多,大家最關心的還是結果吧?根據 TransBench 最新的評測結果(截至 2025 年初的數據參考,實際榜單請見官網即時更新):
當然啦,AI 的世界日新月異,今天的榜首明天可能就有新的挑戰者。所以,最準確的資訊還是要參考 TransBench 官網 的即時榜單。
更讓人興奮的是,TransBench 的評測方法和數據集現在已經開源了!這意味著什麼?這意味著各大 AI 翻譯機構都可以參與進來,進行橫向比較和性能評估。
這一步棋下得非常漂亮:
阿里巴巴國際 AI 業務團隊也表示,隨著翻譯技術的不斷進步,行業對翻譯模型的要求只會越來越高。TransBench 正是順應這種需求而生的評測標準。未來,他們也會繼續專注 AI 技術的應用,幫助更多企業揚帆出海。
TransBench 的出現,對於我們這些普通用戶和企業來說,都是個好消息。
隨著 AI 翻譯市場的競爭日趨白熱化,TransBench 無疑為整個行業提供了一個清晰的參照,也為我們揭示了未來 AI 翻譯的無限可能。
Q1: TransBench 到底是什麼?它跟一般的翻譯軟體有什麼不同? A1: TransBench 本身不是一個翻譯軟體,它是一個 AI 翻譯模型的「評測系統」或「排行榜」。你可以把它想像成 AI 翻譯界的「米其林指南」或「奧運會」,它不直接提供翻譯服務,而是通過一套標準化的方法和數據集,來評估不同 AI 翻譯模型(如 GPT-4o、DeepL 等)在多語言、多場景下的翻譯品質和能力。
Q2: TransBench 和其他翻譯評測標準(比如單純看 BLEU 分數)最大的不同點在哪裡? A2: 最大的不同在於 TransBench 更側重「工業級應用」和「真實場景」。它不僅看傳統的 BLEU 分數(基礎準確性),更引入了像「幻覺率」(避免 AI 胡編亂造)、「文化禁忌詞」、「敬語規範」等與實際商業應用、文化適應性高度相關的指標。同時,它還針對特定行業(如電商)設計了專門的評測維度。
Q3: TransBench 主要評估哪些語言和行業的翻譯能力? A3: TransBench 的目標是覆蓋全球主要語言,目前已包含中文、英文、法文、日文、阿拉伯文等超過 16 種語言。在行業方面,它特別關注電商、客服、市場行銷等需要高度本地化和跨文化適應的領域,並為這些領域建立了專門的評測數據集。
Q4: 我在哪裡可以看到完整的 TransBench 榜單和更詳細的數據? A4: 你可以訪問 TransBench 的官方網站:https://transbench.com/#/rank?lang=zh-cn。網站上會有最新的模型排名、各項評分細節以及評測方法的說明。由於 AI 技術發展迅速,榜單也會持續更新。
Q5: TransBench 的出現對我們一般使用者選擇翻譯工具有什麼實際幫助嗎? A5: 當然有!雖然 TransBench 主要是給行業和開發者看的,但它的評測結果可以間接幫助一般使用者。首先,它能促使翻譯工具開發商提升自家產品的品質。其次,當你需要選擇一個重要的翻譯工具時(比如用於商業文件或重要的跨文化溝通),你可以參考 TransBench 上表現優異的模型背後的技術提供商,作為一個更可靠的選擇依據,而不是單純看廣告或用戶評論。
DMflow.chat:智慧客服新時代,輕鬆切換真人與 AI!持久記憶、客製欄位、即接資料庫表單,多平台溝通,讓服務與行銷更上一層樓。
AI 模型大亂鬥終結者?Google LMEval 讓「模型比武」更公平透明! 還在為比較不同 AI 模型性能而頭痛嗎?Google 推出的開源框架 LMEval,提供標準化評估流程,讓...
告別修 Bug 惡夢?ByteDance 推出 Multi-SWE-bench,AI 自動修復程式碼新里程碑! 還在為修復不同語言的程式碼 Bug 煩惱嗎?ByteDance 的多語言程...

MMLU 測試揭露大型語言模型的真實實力與侷限 核心摘要 當今最先進的人工智慧模型是否真能與人類專家一較高下?MMLU(大規模多任務語言理解測試,Massive Multitask Langu...

圖片來自OpenAI ChatGPT-4o Mini ChatGPT-4o Mini:OpenAI的經濟智能模型 7月18日,OpenAI宣布推出ChatGPT-4o Mini,這是一款旨...
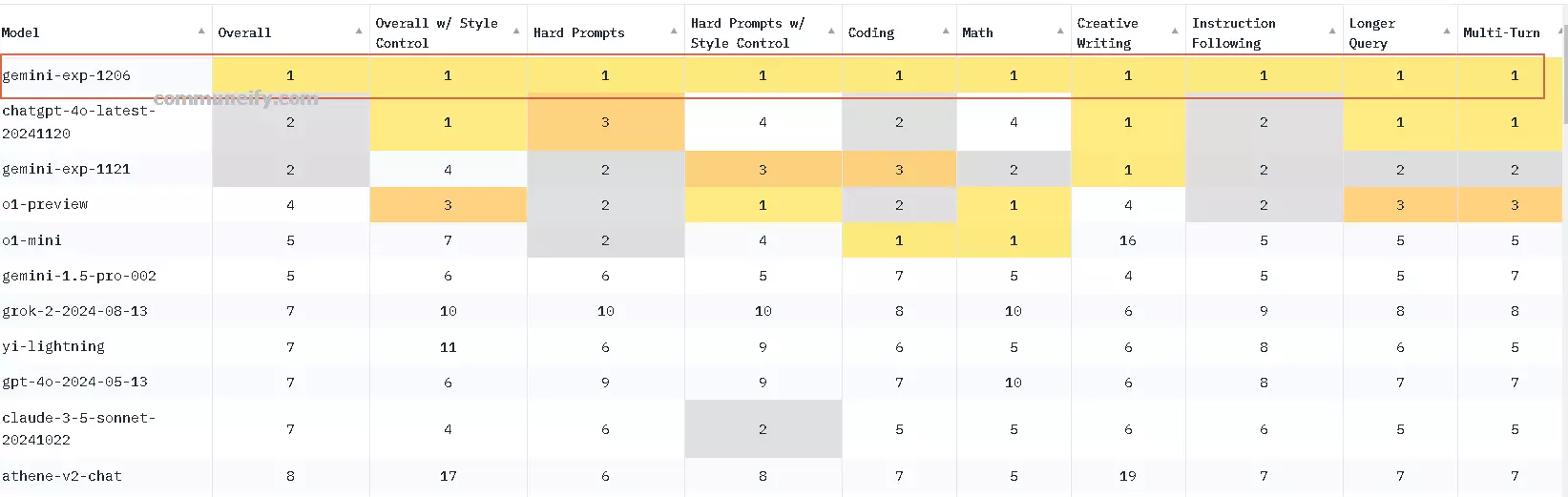
Gemini exp 1206:AI技術的推出 描述 Gemini exp 1206以無與倫比的性能勇奪榜首!它不僅在硬性任務、數學推理、創意寫作等多項指標中均表現優異,更實現了2M的上下文恢...

GitHub 大放送!Copilot AI 程式神助攻免費版來了,開發者們還不快衝? 寫程式卡關?GitHub Copilot AI 助手推出免費版,直接內建在 VS Code!無論你是...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.