tool
Jul 17, 2026
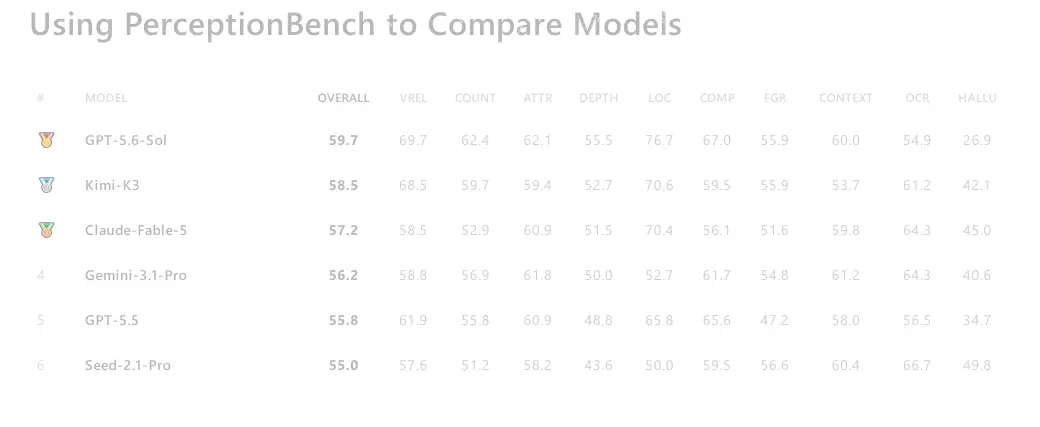
PerceptionBench 揭露 AI 視覺盲點:GPT、Kimi 圖片辨識準確率不到 60%
當最強的 AI 依然會「看錯」圖片:PerceptionBench 帶來的視覺現實震撼 我們常有一種錯覺,覺得現在的大型語言模型連複雜的程式碼都能寫了,看懂一張圖片應該是輕而易舉的 …
Read More →
當最強的 AI 依然會「看錯」圖片:PerceptionBench 帶來的視覺現實震撼 我們常有一種錯覺,覺得現在的大型語言模型連複雜的程式碼都能寫了,看懂一張圖片應該是輕而易舉的 …
AI 助手真的懂人類嗎?解析 VitaBench 2.0 測試平台與長效記憶盲區 現在的人工智能助手在執行明確指令時已經非常厲害了。無論是寫程式碼、算數學,還是預訂機票,只要指令夠 …
告別主觀盲猜!AI 生圖品質怎麼評?全面解析 Qwen-Image-Bench 與專屬裁判 Q-Judger 隨著文字生成圖像技術越來越普及,一個不可避免的難題浮出了水面。誰來決定 …

當大型語言模型開始挑戰「視覺程式碼」,誰才是真正的贏家?本文深入解析 Claude Sonnet 4.5、GPT-5.1、Gemini 3.0 等 9 款頂尖 AI …
Google DeepMind 在其 Gemini 模型於國際數學奧林匹亞(IMO)競賽達到金牌標準後,正式發布 IMO-Bench。這不只是一個評測工具,更是一套推動 AI …
當我們以為大型語言模型(LLM)驅動的 AI 智慧體(Agent)無所不能時,美團 LongCat 團隊發布的最新評測基準 VitaBench 卻給了整個產業一記當頭棒喝。這項堪 …

探索最新的 AI 模型任務完成度評測報告 TaskBench。令人驚訝的是,Gemini 2.5 Flash 等模型在特定任務上的表現超越了許多知名的大型模型。本文將深入解析評測 …
我們總以為 AI 無所不能,但一個簡單的類比時鐘卻讓 Google Gemini 和 OpenAI GPT-5 等頂尖模型紛紛敗下陣來。最新的 ClockBench 基準測試顯 …
AI 總是不夠「聽話」?美團發布全新指令遵循評測基準 Meeseeks,透過獨特的多輪糾錯機制,深度評估 AI 模型是否能真正理解並執行複雜指令。 …

AI 寫程式碼的能力越來越強,但我們如何知道誰才是真正的王者?騰訊混元推出的 AutoCodeBench 是一個全新、高難度的評測基準,涵蓋 20 種程式語言。本文將深入解析其技 …
© 2026 Communeify. All rights reserved.