
DMflow.chat
廣告
全能 DMflow.chat:多平台整合、持久記憶與靈活客製欄位,無需額外開發即可連接資料庫與表單。更支援真人與 AI 的無縫切換,網頁互動加 API 輸出,一步到位!
Google 推出全新一代 AI 模型 Gemini 2.0,標誌著我們邁向智能體時代的重要里程碑。Gemini 2.0 不僅在多模態理解和生成方面取得突破性進展,更具備原生工具使用能力,為打造更強大、更實用的 AI 助理奠定堅實基礎。本文將深入探討 Gemini 2.0 Flash 的各項能力,以及其在不同領域的應用潛力,並重點介紹其與 Gemini 1.5 Pro 和 Gemini 1.5 Flash 在各項基準測試上的效能比較。

圖片來源: https://developers.googleblog.com/en/the-next-chapter-of-the-gemini-era-for-developers/
以下將針對 Gemini 2.0 Flash、Gemini 1.5 Pro 和 Gemini 1.5 Flash 在通用能力、程式碼、事實性、數學、推理、長文本、影像、音訊、影片等多個面向進行效能評測,並詳細解釋各項測試的意義。
Gemini 2.0 Flash,添加輸出多模態,你可以測試語音輸出、以及螢幕共享功能(可以讓Gemini讀取你的螢幕),但不支援中文(能聽懂,但無法說,中文目前會轉成其他語言),你可以在底下連結直接stream live使用
https://aistudio.google.com/app/live
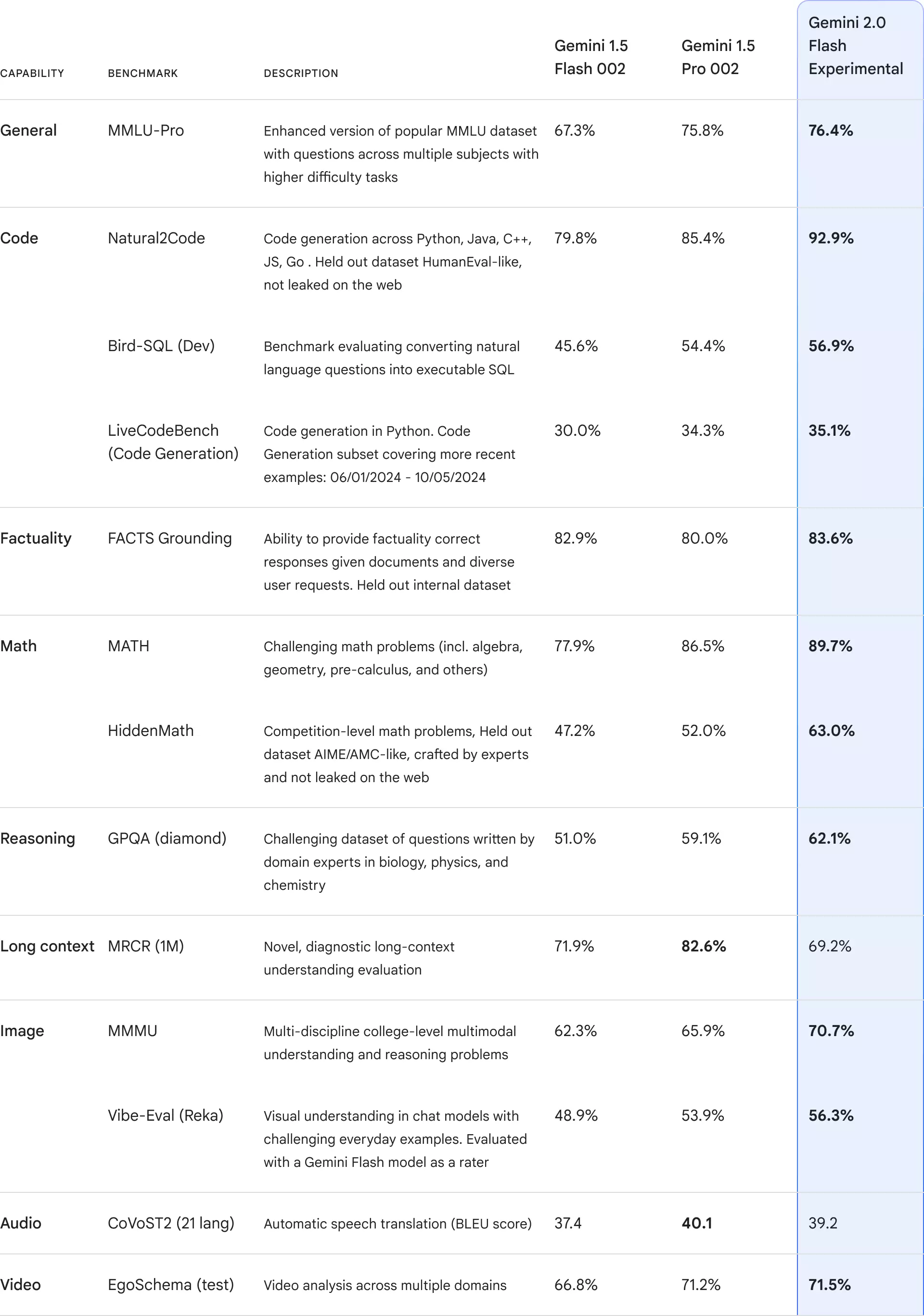
MMLU-Pro 是廣受歡迎的 MMLU 數據集的升級版,涵蓋更多學科和更高難度的問題。這項測試旨在評估模型在廣泛知識領域的理解和推理能力。
詳細說明: MMLU-Pro 包含 57 個學科,涵蓋人文、社會科學、STEM 等多個領域。每個問題都以多選題的形式呈現,需要模型具備廣泛的知識儲備和跨學科的推理能力才能正確作答。
結果分析: Gemini 2.0 Flash 在 MMLU-Pro 測試中取得了 76.4% 的優異成績,超越了 Gemini 1.5 Flash,並略微領先於 Gemini 1.5 Pro。這表明 Gemini 2.0 Flash 在通用知識理解和推理方面有顯著提升。
程式碼能力測試主要評估模型在理解和生成程式碼方面的能力,包含 Natural2Code 和 Bird-SQL (Dev) 以及 LiveCodeBench 三項測試。
Natural2Code 評估模型在 Python、Java、C++、JS、Go 等多種程式語言的程式碼生成能力。此測試採用了類似 HumanEval 的數據集,但確保數據集未在網路上洩露。
詳細說明: Natural2Code 測試要求模型根據自然語言描述生成相應的程式碼。這項測試考驗模型對程式語言語法、語義和程式邏輯的理解能力。
結果分析: Gemini 2.0 Flash 在 Natural2Code 測試中取得了高達 92.9% 的驚人成績,大幅領先於 Gemini 1.5 系列模型。這表明 Gemini 2.0 Flash 在程式碼生成方面具有極強的能力,有助於提升程式開發效率。
Bird-SQL (Dev) 評估模型將自然語言問題轉換為可執行 SQL 查詢的能力。
詳細說明: 這項測試需要模型理解自然語言描述的數據查詢需求,並將其轉換為正確的 SQL 語句。這項測試考驗模型對數據庫結構和 SQL 語法的掌握程度。
結果分析: Gemini 2.0 Flash 在 Bird-SQL (Dev) 測試中獲得了 56.9% 的分數,相比於 Gemini 1.5 系列模型有所提升,這表示其在理解自然語言查詢意圖並生成對應 SQL 語句的能力上更進一步。
LiveCodeBench (程式碼生成) 是針對 Python 程式碼生成的評測基準,其數據集涵蓋了從 2024 年 1 月到 2024 年 10 月 5 日的最新程式碼範例。
詳細說明: 這項測試專注於評估模型生成最新 Python 程式碼的能力,反映模型對程式語言最新發展和最佳實踐的掌握程度。
結果分析: Gemini 2.0 Flash 在 LiveCodeBench 測試中獲得 35.1% 的分數,略高於 Gemini 1.5 系列模型,表示其能夠更好地應對最新的程式碼生成挑戰。
FACTS Grounding 測試模型提供基於事實的正確回覆的能力,並使用內部數據集進行評估。
詳細說明: 這項測試要求模型根據給定的文件和用戶問題,提供準確且基於事實的回覆。這項測試考驗模型的信息檢索、理解和整合能力。
結果分析: Gemini 2.0 Flash 在 FACTS Grounding 測試中取得了 83.6% 的成績,優於 Gemini 1.5 Pro,顯示其在提供基於事實的準確回覆方面更具優勢。
數學能力測試評估模型解決數學問題的能力,包含 MATH 和 HiddenMath 兩項測試。
MATH 測試模型解決各種數學問題的能力,包括代數、幾何、微積分等。
詳細說明: MATH 數據集包含了各種難度的數學問題,要求模型具備紮實的數學基礎和邏輯推理能力才能正確解答。
結果分析: Gemini 2.0 Flash 在 MATH 測試中取得了 89.7% 的高分,顯著優於 Gemini 1.5 系列模型,這表明其在解決各種數學問題方面具有出色的能力。
HiddenMath 測試模型解決競賽級別的數學問題的能力,採用了 AIME/AMC 類型的數據集,這些數據集由專家編寫且未在網路上洩露。
詳細說明: HiddenMath 的題目難度更高,通常需要更深入的數學知識和更複雜的推理步驟才能解決。
結果分析: Gemini 2.0 Flash 在 HiddenMath 測試中取得了 63.0% 的成績,大幅領先於 Gemini 1.5 系列模型,這充分證明了其在解決高難度數學問題方面的卓越能力。
GPQA (diamond) 評估模型在生物學、物理學和化學等領域的專家級問題上的推理能力。
詳細說明: GPQA (diamond) 數據集由相關領域的專家編寫,問題的難度和專業性都非常高,需要模型具備深厚的專業知識和強大的推理能力才能解答。
結果分析: Gemini 2.0 Flash 在 GPQA (diamond) 測試中獲得了 62.1% 的分數,超越了 Gemini 1.5 系列模型,表明其在專業領域的推理能力得到顯著提升。
MRCR (1M) 評估模型在長文本上的理解和推理能力。
詳細說明: MRCR (1M) 測試要求模型理解並推理長達 100 萬個 token 的文本內容。這項測試考驗模型對長文本的記憶、理解和推理能力。
結果分析: Gemini 1.5 Pro 在此項目中表現最佳,Gemini 2.0 Flash 則略遜於 Gemini 1.5 Flash。這可能與 Gemini 2.0 Flash 的模型架構和訓練策略有關,未來仍有優化空間。
影像理解能力測試評估模型對影像內容的理解和推理能力,包含 MMMU 和 Vibe-Eval (Reka) 兩項測試。
MMMU 評估模型在多學科大學程度的多模態理解和推理問題上的表現。
詳細說明: MMMU 數據集包含了來自不同學科的影像和文本,要求模型能夠理解影像內容,並結合文本信息進行推理。
結果分析: Gemini 2.0 Flash 在 MMMU 測試中取得了 70.7% 的成績,優於 Gemini 1.5 系列模型,顯示其在多模態理解和推理方面有顯著提升。
Vibe-Eval (Reka) 評估模型在聊天機器人場景中對影像的理解能力,並採用 Gemini Flash 模型作為評估者。
詳細說明: 這項測試專注於評估模型在對話場景中理解影像內容的能力,更貼近實際應用場景。
結果分析: Gemini 2.0 Flash 在 Vibe-Eval (Reka) 測試中獲得了 56.3% 的分數,優於 Gemini 1.5 系列模型,顯示其在對話場景中的影像理解能力有所提升。
CoVoST2 (21 lang) 評估模型的自動語音翻譯能力 (BLEU 分數)。
詳細說明: CoVoST2 數據集包含了 21 種語言的語音數據,要求模型將語音翻譯成目標語言的文本。
結果分析: Gemini 1.5 Pro 在此項目中表現最佳,Gemini 2.0 Flash 則略遜於 Gemini 1.5 Pro。這表明 Gemini 2.0 Flash 在自動語音翻譯方面還有待提升。
EgoSchema (test) 評估模型在多個領域的影片分析能力。
詳細說明: EgoSchema 數據集包含了各種場景的第一人稱視角影片,要求模型理解影片內容並回答相關問題。
結果分析: Gemini 2.0 Flash 在 EgoSchema (test) 測試中取得了 71.5% 的成績,略微優於 Gemini 1.5 Pro,顯示其在影片分析能力方面有一定提升。
Gemini 2.0 的強大能力為 AI 智能體的發展開闢了新的可能性。Google 正在積極探索 Gemini 2.0 在各個領域的應用,包括:
Google 始終將負責任地發展 AI 技術放在首位。在開發 Gemini 2.0 的過程中,Google 採取了多項措施確保其安全性和可靠性,包括:
Gemini 2.0 的推出標誌著 AI 技術發展的一個重要里程碑。其在多個領域的卓越表現,特別是在程式碼生成、數學和推理方面的顯著提升,為 AI 智能體的發展奠定了堅實基礎。未來,Google 將繼續探索 Gemini 2.0 的潛力,並負責任地將其應用於各個領域,推動 AI 技術的發展,為人類社會帶來更多福祉。
以下整理了關於 Gemini 2.0 的幾個關鍵問題與解答,幫助您更深入了解這個劃時代的 AI 模型:
Q1: Gemini 2.0 Flash 和 Gemini 1.5 Pro 相比,哪個更強大?
A1: 在大多數基準測試中,Gemini 2.0 Flash 的表現都優於或與 Gemini 1.5 Pro 相當,特別是在程式碼生成、數學和推理方面有顯著提升。然而,在長文本理解和自動語音翻譯方面,Gemini 1.5 Pro 仍有一定優勢。總體而言,Gemini 2.0 Flash 是一款更強大、更均衡的模型。
Q2: Gemini 2.0 可以用來做什麼?
A2: Gemini 2.0 的應用前景非常廣泛,可以用於:
Q3: 如何使用 Gemini 2.0?
A3: 目前,Gemini 2.0 Flash 作為實驗性模型,已透過 Google AI Studio 和 Vertex AI 向開發者提供。普通用戶可以透過 Gemini 應用程式 (即將支援) 體驗到針對聊天優化的 Gemini 2.0 Flash 版本。Google 計劃在 2025 年初將 Gemini 2.0 擴展到更多 Google 產品中。
Q4: Gemini 2.0 安全嗎?
A4: Google 始終將負責任地發展 AI 技術放在首位。在開發 Gemini 2.0 的過程中,Google 採取了多項措施確保其安全性和可靠性,包括風險評估、安全訓練、多模態安全評估、隱私保護和防止濫用等。Google 將繼續致力於負責任地發展 AI 技術,並與外部專家合作,確保 AI 技術的安全和可靠。
全能 DMflow.chat:多平台整合、持久記憶與靈活客製欄位,無需額外開發即可連接資料庫與表單。更支援真人與 AI 的無縫切換,網頁互動加 API 輸出,一步到位!
Google Gemini 2.5 Pro API 定價公布:開發者熱議,使用量激增 80% Google 正式公布了備受期待的 Gemini 2.5 Pro API 定價方案。雖然價格...
Gemini 2.5:Google 最強 AI 模型,邏輯推理與編碼能力再突破! 突破極限的 AI 智能——Gemini 2.5 誕生 Google 正式推出 Gemini 2.5,這是迄今...
Google AI Studio 現可透過 ai.dev 網域直接訪問! 簡單好記,Google AI Studio 進入全新時代 Google 今日正式宣布,開發者熟悉的 Google A...
Google AI Studio 影像生成功能升級:更低誤判率、更強大易用性 Google AI Studio 的重大更新:更準確、更高效的 AI 影像生成 Google 最近對其 AI 開...
Google Gemini 推出 Canvas 協作工作區與 Audio Overview 音訊摘要功能 讓 AI 更具互動性與創造力的新工具 Google 近日為旗下 AI 助手 Gemi...
Google Gemini 2.0 Flash 水印去除功能引發版權爭議 Google AI 新功能再掀版權風暴? 於先前發表的文章Google Gemini 2.0 Flash 解鎖原生圖...
還在手動找資料?Google NotebookLM 新增「探索來源」功能,讓 AI 幫你搞定! Google NotebookLM 推出超方便的「探索來源」新功能!只要輸入你想了解的主題...

GraphRAG:利用知識圖譜增強自然語言生成的創新方法 GraphRAG 是一種先進的結構化檢索增強生成(RAG)方法,利用知識圖譜提升大型語言模型(LLM)的推理能力和答案準確性,特別適用...

X平台Grok AI免費試用開放!API同步釋出,開發者也能免費體驗! X平台重磅宣布Grok AI推出免費試用服務,讓一般用戶也能親身體驗其強大功能!同時,Grok API也同步釋出,...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.