重大突破:平價訓練高效能 AI 模型成為可能
UC Berkeley 的 NovaSky 團隊最近發表了一項重大突破 - Sky-T1-32B-Preview AI 模型。這個開創性的專案不僅展現了與頂級專有模型相媲美的推理能力,更令人驚訝的是,整個訓練過程的成本僅需 450 美元以下。最重要的是,這個專案採用完全開源的方式,為學術界和開源社群帶來重大貢獻。
革命性的模型架構與訓練方法
Sky-T1-32B-Preview 的成功關鍵在於其創新的訓練方法:
資料處理的突破
- 團隊精心策劃了 17,000 個多樣化的訓練範例
- 採用 Still-2 啟發的資料重組技術,提升模型的資訊理解能力
- 透過拒絕採樣技術提升資料品質,使編碼測試的準確率從 25% 提升至 90% 以上
高效能訓練流程
- 以 Qwen2.5-32B-Instruct 為基礎模型
- 使用 8 台 H100 GPU 進行訓練
- 採用 DeepSpeed Zero-3 技術優化運算效能
- 整個訓練過程僅需 19 小時,成本控制在 450 美元以下
卓越的效能表現
Sky-T1-32B-Preview 在多項基準測試中展現出優異的表現:
數學推理能力
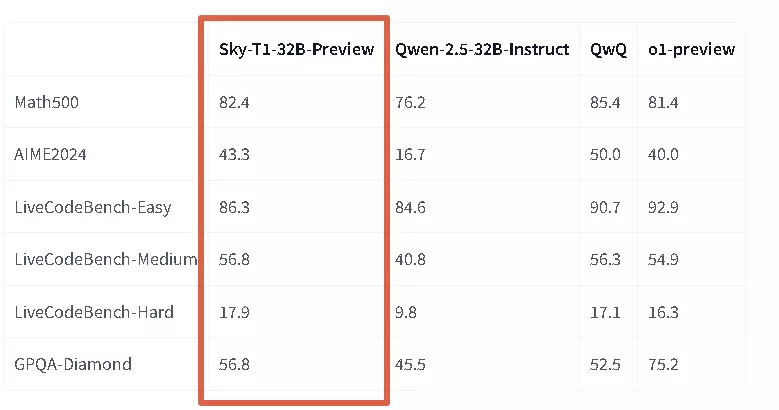
- Math500 測試:獲得 82.4 分,接近領先的 QwQ(85.4 分)
- AIME2024:達到 43.3 分,超越 o1-preview(40.0 分)
- GPQA-Diamond:獲得 56.8 分,明顯優於 Qwen-2.5(45.5 分)
程式編碼能力
- LiveCodeBench-Easy:86.3 分
- LiveCodeBench-Medium:56.8 分
- LiveCodeBench-Hard:17.9 分,略高於 o1-preview
重要研究發現
模型規模的重要性
研究團隊發現,較小規模的模型(7B 和 14B)在效能提升上有限,往往產生重複或較不有效的輸出。32B 的規模被證實是處理推理任務的最佳選擇。
資料混合的平衡
在訓練過程中,數學和編碼資料的平衡至關重要:
- 初期加入編碼資料時,確實降低了數學表現
- 透過增加具有挑戰性的問題來豐富資料集
- 最終在保持數學準確度的同時,提升了編碼能力
未來展望與影響
Sky-T1-32B-Preview 的成功為 AI 研究帶來新的可能性:
技術發展方向
- 持續優化模型效能
- 探索更先進的測試時期效能提升技術
- 致力於提高準確度
對產業的影響
- 降低 AI 研究的門檻
- 促進學術界和開發者的創新
- 加速開源 AI 模型的發展
開源貢獻
- 完整開放原始碼
- 提供模型權重
- 分享訓練和評估工具
- 詳細的技術文件
常見問題
Q1:為什麼 Sky-T1-32B-Preview 的訓練成本如此低? A1:主要得益於優化的訓練流程和 DeepSpeed Zero-3 技術的應用,使得整個訓練過程高度效率化。
Q2:這個模型與其他商業模型相比有什麼優勢? A2:最大的優勢在於完全開源,同時在多項測試中展現出與頂級商業模型相當的效能。
Q3:開發者如何使用這個模型? A3:開發者可以透過開源程式碼庫取得完整的模型權重、訓練資料和部署工具。
這項突破性的研究不僅展現了高效能 AI 模型的民主化可能性,更為整個 AI 研究社群開創了新的發展方向。透過開源共享和創新的訓練方法,Sky-T1-32B-Preview 為未來的 AI 發展寫下了重要的一頁。
參考資料
相關連結

DMflow.chat
DMflow.chat: 您的智能AI夥伴,提升客戶互動、創造卓越體驗。
Learn More
videoweaver.app
Video Weaver: 瀏覽器內完成專業影片剪輯,無需下載、即刻創作。
Learn More
scribis.app
Scribis: 字幕編輯、語音轉錄文字、即時顯示轉錄文字。
Learn More
DMflow.chat
探索DMflow.chat,立即開啟AI驅動的客戶服務新時代。
Learn MoreDMflow.chat
DMflow.chat: 您的智能AI夥伴,提升客戶互動、創造卓越體驗。
Learn Morevideoweaver.app
Video Weaver: 瀏覽器內完成專業影片剪輯,無需下載、即刻創作。
Learn Morescribis.app
Scribis: 字幕編輯、語音轉錄文字、即時顯示轉錄文字。
Learn MoreDMflow.chat
探索DMflow.chat,立即開啟AI驅動的客戶服務新時代。
Learn More