近年來,AI 在程式設計領域的應用越來越廣泛,但它到底能做到什麼程度?最近,OpenAI 公布了一項重要報告,詳細評估了 AI 在軟體開發中的實際表現,並透過一個價值 100 萬美元的真實開發專案進行測試。這項基準測試名為 SWE-Lancer,涵蓋 1,400 個來自 Upwork 的真實專案,並從兩大核心方面——直接開發與專案管理——來評估 AI 的能力。
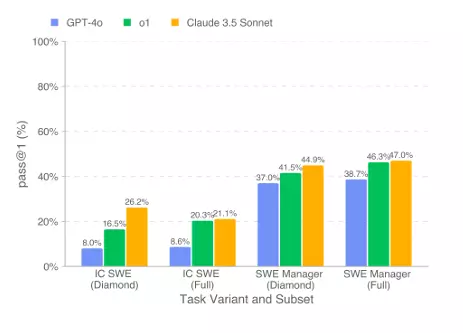
Claude 3.5 Sonnet 表現最佳,成功率達 26.2%
測試結果顯示,在目前公開可用的 AI 模型中,Anthropic 推出的 Claude 3.5 Sonnet 表現最優秀,其在純編碼任務的成功率達到了 26.2%,而在專案管理決策上的正確率則達到 44.9%。
這意味著,在程式設計的某些部分,AI 確實可以發揮作用,尤其是處理相對單純的任務,例如修復 API 調用錯誤或簡單的程式碼優化。然而,對於需要更深入理解和創意解決方案的複雜專案(例如開發跨平台影音播放功能),AI 仍然顯得力不從心。事實上,測試中發現 AI 雖然能辨識出問題區塊,但經常無法理解問題的根本原因,更別說提供完整的解決方案。
AI 在開發市場的經濟價值
從經濟效益角度來看,數據顯示,在公開的 Diamond 資料集中,AI 能夠完成價值約 208,050 美元的開發工作。如果擴展至完整數據集,則 AI 預計可處理超過 40 萬美元的專案工作量。這表明,AI 在軟體開發中的應用已經具備一定的經濟價值,尤其是對於企業來說,AI 可能能夠大幅降低人力成本,並提升部分開發效率。
為何 GPT-4o 未被納入測試?
值得注意的是,OpenAI 並未在這次測試中納入最新的 GPT-4o(內部代號 o3)。目前唯一的參考點來自去年 8 月 OpenAI 釋出的 SWE-Bench Verified 測試結果,當時 GPT-4o 取得了 33% 的分數,而更新後的 o3 推理模型更是達到了 72%(OpenAI, 2024b)。這樣看來,GPT-4o 可能已經遠超 SWE-Lancer 測試中的所有模型,那麼為何不納入比較?
有幾種可能性:
- 數據時效性——這次 SWE-Lancer 測試可能基於較舊的數據,而 GPT-4o 可能尚未經過最佳化,因此未被納入。
- 策略性考量——如果 GPT-4o 表現明顯領先 OpenAI 競爭對手,可能會對市場預期產生影響,甚至影響 OpenAI 未來新模型的推出時機。
- 測試範圍適配性——GPT-4o 的設計可能更適用於即時推理與多模態處理,而 SWE-Lancer 偏重純粹的程式設計能力。
無論原因為何,這次測試結果確實讓 Claude 3.5 Sonnet 站上了舞台,成為目前最被關注的 AI 程式設計模型之一。
AI 程式設計的未來發展方向
雖然 AI 目前在軟體開發中仍有諸多限制,但它的潛力不容小覷。未來 AI 在這個領域的發展,可能會聚焦於以下幾點:
- 增強對程式碼語境的理解能力——AI 需要更深入地理解程式碼的整體架構,而不只是表面上的錯誤修正。
- 更強的推理與決策能力——目前 AI 主要依賴統計模式,但未來可能會結合更複雜的邏輯推理機制。
- 人機協作的最佳化——AI 可能不會完全取代人類開發者,而是作為輔助工具,幫助工程師更高效地完成專案。
總的來說,這場 AI 與人類開發者的競賽還遠未結束。無論 OpenAI 是否刻意避開 GPT-4o 的比較,SWE-Lancer 的結果已經證明 AI 正在以驚人的速度提升。或許,是時候重新審視 Anthropic 的技術進展了!
資料來源

DMflow.chat
DMflow.chat: 您的智能AI夥伴,提升客戶互動、創造卓越體驗。
Learn More
DMflow.chat
探索DMflow.chat,立即開啟AI驅動的客戶服務新時代。
Learn More
videoweaver.app
Video Weaver: 瀏覽器內完成專業影片剪輯,無需下載、即刻創作。
Learn More
scribis.app
Scribis: 字幕編輯、語音轉錄文字、即時顯示轉錄文字。
Learn MoreDMflow.chat
DMflow.chat: 您的智能AI夥伴,提升客戶互動、創造卓越體驗。
Learn MoreDMflow.chat
探索DMflow.chat,立即開啟AI驅動的客戶服務新時代。
Learn Morevideoweaver.app
Video Weaver: 瀏覽器內完成專業影片剪輯,無需下載、即刻創作。
Learn Morescribis.app
Scribis: 字幕編輯、語音轉錄文字、即時顯示轉錄文字。
Learn More