近來,AI 技術的進步讓大型語言模型(LLM)變得愈發強大,然而,這些模型在處理資訊時產生「幻覺」(hallucination)——即生成錯誤或虛假的資訊——仍是一大挑戰。為了評估不同模型在資訊準確性上的表現,Vectara 推出了「幻覺排行榜」(Hallucination Leaderboard),並使用 Hughes 幻覺評估模型(HHEM-2.1)來測試 LLM 在摘要文件時產生錯誤資訊的頻率。
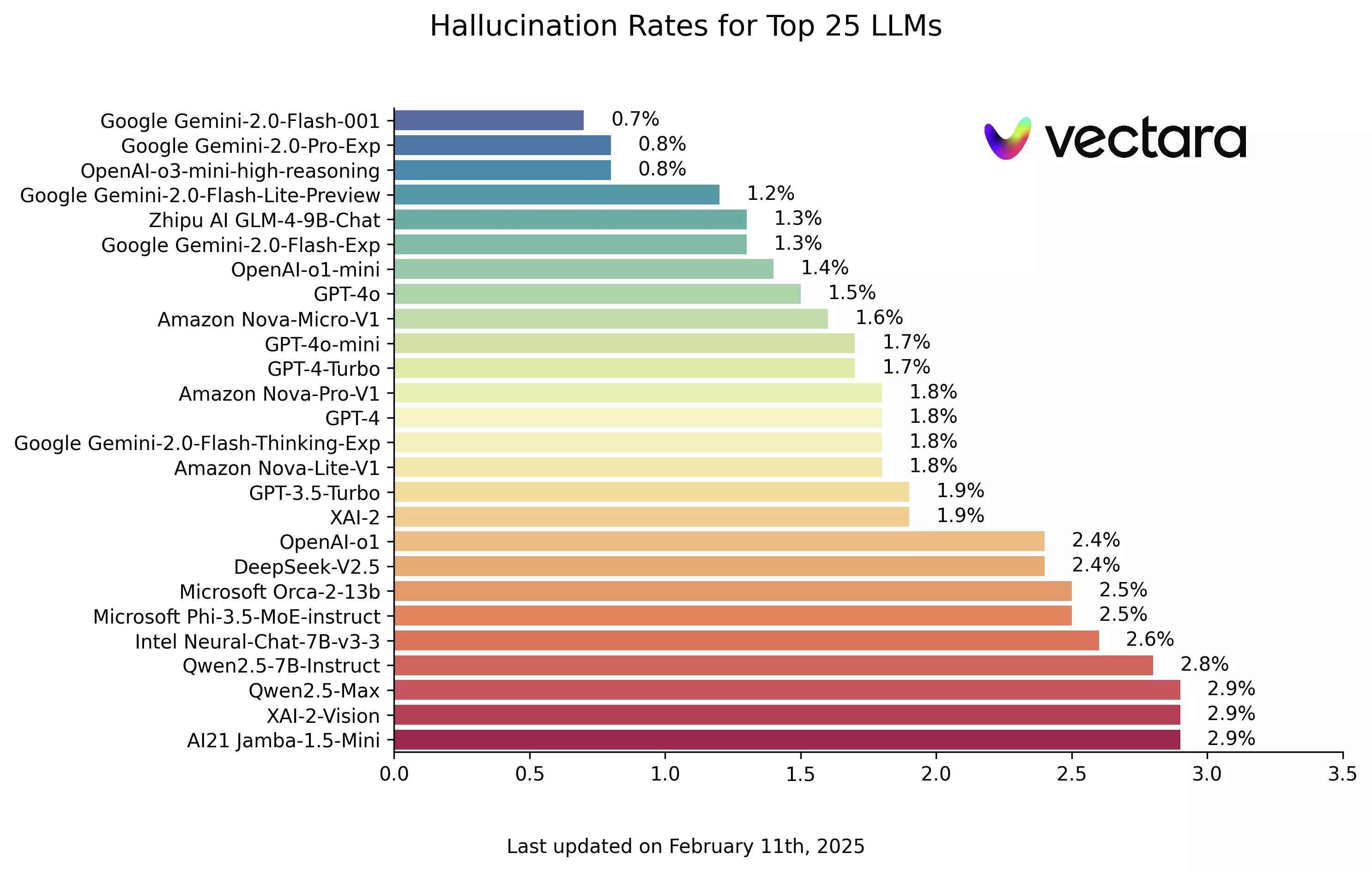
Gemini 2.0 Flash 以 0.7% 的幻覺率稱霸榜單
最新排行榜顯示,Google 的 Gemini 2.0 Flash-001 模型表現卓越,幻覺率僅 0.7%,幾乎不會在文件處理過程中引入錯誤資訊。這意味著,它能夠以極高的準確度生成內容,為用戶提供可靠的摘要。
緊隨其後的則是 Gemini-2.0-Pro-Exp 與 OpenAI 的 o3-mini-high-reasoning,這兩款模型的幻覺率同為 0.8%。這一結果顯示,頂尖 LLM 已經在資訊準確性方面取得重大突破。
排行榜重點指標解析
該報告不僅關注幻覺率,還評估了其他關鍵指標,包括:
- 事實一致性率(Factual Consistency Rate):多數模型的準確性超過 95%,確保內容的真實性。
- 回答率(Answer Rate):大多數模型的回答率接近 100%,說明它們能夠高效處理用戶輸入並給出回應。
- 平均摘要長度(Average Summary Length):不同模型的摘要長度有所差異,這可能反映它們在資訊壓縮與表達能力上的不同。
模型表現對比
以下是排行榜中的部分數據:
| 模型名稱 | 幻覺率 | 事實一致性率 | 回答率 | 平均摘要長度(字數) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7% | 99.3% | 100.0% | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8% | 99.2% | 99.7% | 61.5 |
| OpenAI o3-mini-high-reasoning | 0.8% | 99.2% | 100.0% | 79.5 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2% | 98.8% | 99.5% | 60.9 |
| Zhipu AI GLM-4-9B-Chat | 1.3% | 98.7% | 100.0% | 58.1 |
| OpenAI o1-mini | 1.4% | 98.6% | 100.0% | 78.3 |
| GPT-4o | 1.5% | 98.5% | 100.0% | 77.8 |
從這份數據可以看出,Google 的 Gemini 系列與 OpenAI 的新一代模型在減少幻覺方面均表現優異。其中,Gemini 2.0 Flash-001 無疑成為新一代 LLM 的領頭羊。
為何幻覺率如此重要?
大型語言模型被廣泛應用於新聞摘要、醫學資訊、法律分析等領域,確保資訊的準確性至關重要。如果 LLM 無法提供可靠的資訊,可能會導致錯誤的決策或誤導公眾。因此,降低幻覺率是未來 AI 研究與應用的一大核心目標。
未來展望:AI 會變得更「可信」嗎?
隨著 AI 技術的不斷進步,幻覺率的降低無疑是一個好消息。然而,LLM 仍然無法完全消除錯誤,開發者仍需持續改進模型的資訊過濾能力。同時,用戶也應該對 AI 生成的內容保持一定的批判性,透過多方驗證來確保資訊的真實性。
想要查看完整排行榜?請點擊這裡查看 Vectara 的官方數據。
這份最新的「幻覺排行榜」為研究人員、開發者以及普通用戶提供了有價值的參考,幫助大家了解當前 LLM 的表現,並為未來的 AI 發展方向提供指引。

videoweaver.app
Video Weaver: 瀏覽器內完成專業影片剪輯,無需下載、即刻創作。
Learn More
DMflow.chat
探索DMflow.chat,立即開啟AI驅動的客戶服務新時代。
Learn More
scribis.app
Scribis: 字幕編輯、語音轉錄文字、即時顯示轉錄文字。
Learn More
DMflow.chat
DMflow.chat: 您的智能AI夥伴,提升客戶互動、創造卓越體驗。
Learn Morevideoweaver.app
Video Weaver: 瀏覽器內完成專業影片剪輯,無需下載、即刻創作。
Learn MoreDMflow.chat
探索DMflow.chat,立即開啟AI驅動的客戶服務新時代。
Learn Morescribis.app
Scribis: 字幕編輯、語音轉錄文字、即時顯示轉錄文字。
Learn MoreDMflow.chat
DMflow.chat: 您的智能AI夥伴,提升客戶互動、創造卓越體驗。
Learn More