What is DeepGEMM?
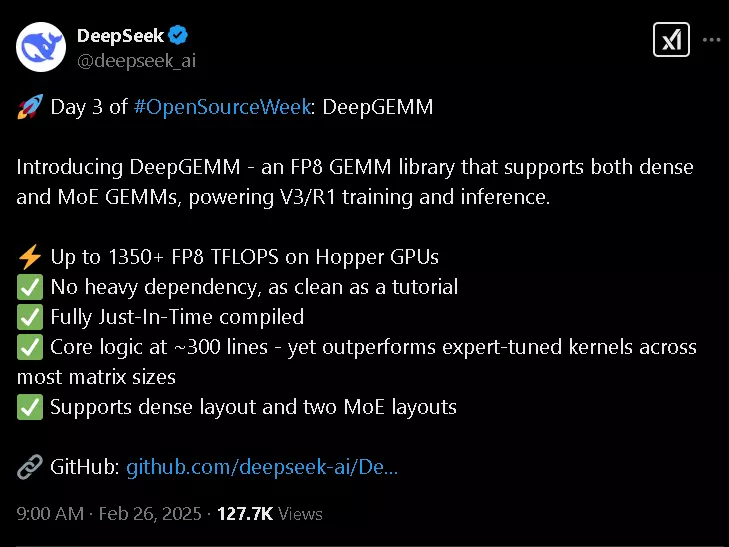
DeepSeek has just unveiled DeepGEMM on the third day of its “Open Source Week,” and the AI community is already buzzing. DeepGEMM is an open-source library supporting FP8 General Matrix Multiplication (GEMM), specifically designed for both intensive and Mixture-of-Experts (MoE) matrix operations. This release directly powers the training and inference processes for DeepSeek’s flagship models — DeepSeek V3 and R1.
But what makes DeepGEMM stand out? Let’s break it down.
Blazing-Fast Performance with Minimal Complexity
According to DeepSeek’s official announcement on X (formerly Twitter), DeepGEMM delivers a staggering 1350+ TFLOPS of FP8 computing performance when running on NVIDIA Hopper GPUs. What’s even more impressive is that its core logic consists of only around 300 lines of code — a remarkable balance of simplicity and speed.
Here’s a snapshot of what DeepGEMM brings to the table:
- No complicated dependencies — skip the headache of bloated libraries.
- Just-In-Time (JIT) compilation — all kernels are compiled at runtime, so there’s no lengthy installation process.
- Supports both dense and MoE layouts — giving developers flexibility to handle complex AI models.
- Clean, tutorial-style design — perfect for those who want to learn FP8 matrix multiplication from scratch.
DeepGEMM vs. Expert-Tuned Libraries — How Does It Stack Up?
Performance is key in AI model training, and DeepGEMM doesn’t disappoint. In fact, it consistently matches or even outpaces expert-tuned libraries across various matrix sizes.
Normal GEMMs for Dense Models (Speedups Compared to CUTLASS 3.6)
| M | N | K | Computation (TFLOPS) | Speedup |
|---|---|---|---|---|
| 64 | 2112 | 7168 | 206 | 2.7x |
| 128 | 2112 | 7168 | 352 | 2.4x |
| 4096 | 2112 | 7168 | 1058 | 1.1x |
Grouped GEMMs for MoE Models (Masked Layout)
| Groups | M per Group | N | K | Computation (TFLOPS) | Speedup |
|---|---|---|---|---|---|
| 1 | 1024 | 4096 | 7168 | 1233 | 1.2x |
| 2 | 512 | 7168 | 2048 | 916 | 1.2x |
| 4 | 256 | 4096 | 7168 | 932 | 1.1x |
While DeepGEMM shows incredible speedups, the team is open about areas that still need fine-tuning. Some matrix shapes don’t perform as well, and they’re inviting the community to submit optimization pull requests (PRs).
Why Should Developers Care?
DeepSeek isn’t just building tools for themselves — they’re investing in open collaboration. By releasing DeepGEMM, they’re giving developers worldwide a chance to push AI training and inference even further. It’s not just about DeepSeek’s models — it’s about creating an ecosystem where innovation moves at the speed of thought.
Plus, for those diving into FP8 matrix operations, DeepGEMM’s clean design means you can study the Hopper tensor cores without wading through complicated, over-engineered code.
Getting Started with DeepGEMM
Ready to test out DeepGEMM? Here’s what you need to get started:
Requirements:
- NVIDIA Hopper architecture GPUs (sm_90a)
- Python 3.8 or higher
- CUDA 12.3 or higher (12.8 recommended)
- PyTorch 2.1 or higher
- CUTLASS 3.6 (can be cloned via Git submodule)
You can access the full project and installation guide here: DeepGEMM on GitHub
The Road Ahead
DeepSeek’s Open Source Week has already introduced us to FlashMLA (a fast language model architecture) and DeepEP (expert parallel communication). With DeepGEMM, they’re further solidifying their place in the AI infrastructure space.
But this is just the beginning. With community contributions, DeepGEMM could evolve into an even more powerful tool — not just for DeepSeek’s models but for AI research at large.
So, are you ready to roll up your sleeves and explore what FP8 GEMMs can do? Let’s build the future of AI, one matrix at a time.

DMflow.chat
DMflow.chat: Your intelligent AI partner for exceptional customer engagement.
Learn More
videoweaver.app
Video Weaver: Professional video editing directly in your browser. No downloads required.
Learn More
scribis.app
Scribis: Subtitle editing, audio transcription, and live transcription.
Learn More
DMflow.chat
Discover DMflow.chat and unlock the new era of AI-powered customer service.
Learn MoreDMflow.chat
DMflow.chat: Your intelligent AI partner for exceptional customer engagement.
Learn Morevideoweaver.app
Video Weaver: Professional video editing directly in your browser. No downloads required.
Learn Morescribis.app
Scribis: Subtitle editing, audio transcription, and live transcription.
Learn MoreDMflow.chat
Discover DMflow.chat and unlock the new era of AI-powered customer service.
Learn More